CS 267 Homework Assignment 1
Sukun Kim and Scott Hafeman
September 18th, 2002
Purpose
During this assignment, we investigated, analyzed and attempted to optimize the performance of standard matrix-matrix multiplication for increasingly large matrices.
Summary
We achieved a peak average performance of 220 Mflops/s for square matrix multiplication between N=20 and N=512. These results show a factor of up to 30 times speedup is achieved compared to the basic “naïve” matrix multiplication compiled using minimal compiler options.
We attempted changes to the matrix multiplication algorithm such as: loop unrolling, explicit pre-loading, explicit use of registers, inter- and intra-block traversal order, interchanging the order of loops and the elimination of function calls. We found that the key optimizations were selecting compiler options, transposing the matrix structure before computation and calculating two partial sums simultaneously in the inner loop.
Figure 1 below illustrates the algorithm performance in millions of floating point operations per second (Mflops/s) observed when averaged over five trials. Performance on a Millennium Katmai node using the basic and optimized algorithms is shown as well as the performance on the development/test platform.
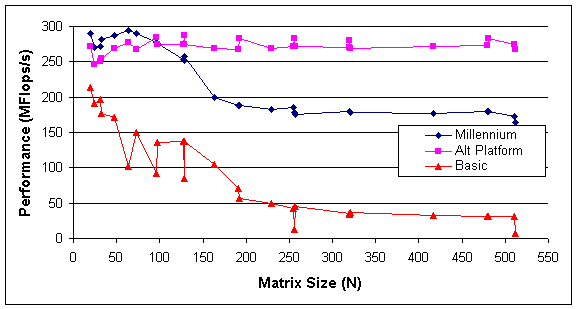
Figure 1 Comparison of the Optimized Algorithm on Millennium, Alt. Platform and the Basic algorithm
Motivation for a better Matrix Multiplication Algorithm
Figure 2 shows the performance of the naïve matrix-matrix multiplication algorithm versus square matrix size N. It is evident that this algorithm is not scalable since greater than 100 Mflops/s performance is sustained for values of N<96 and falls off to less than 10 Mflops/s at N=512.
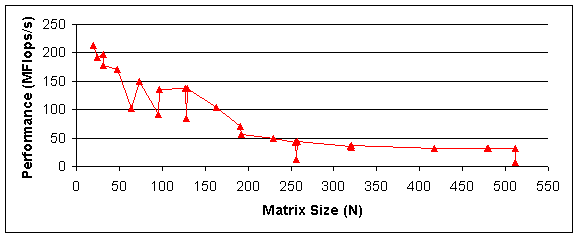
Figure 2 Performance of the Naïve matrix-matrix multiplication algorithm versus matrix size
The main reason for this behavior stems from the non-ideal stride distance through the matrix. For larger matrices, each stride falls beyond the data that is contained within the 16KB L1 data cache (512 lines @ 32 bytes each) or the 512KB L2 cache (4K lines @ 128 bytes each). The address aliasing phenomenon occurs within the cache causing excessive cache misses for specific values of N. Periodic cache misses become more frequent beyond N = 128 and restrict the performance beyond N = 196.
Performance degradation is extremely severe when N is a multiple of 256. This situation corresponds to address aliasing. When N=256, a stride of 2KB occurs causing the desired address to map to the previously accessed cache block in the L1 cache. Since this cache is four-way associative, once the 2KB stride is taken more than four times, thrashing between the four cache locations will occur leading to excessive cache misses.
The page size in memory of 4 KB leads to the likely occurrence of a page fault when N=512 shown by the poor 7.7 Mflops/s performance. Both phenomena occur periodically but less frequently for lower powers of two (128, 64 and 32) accounting for those performance dips.
This detrimental behavior observed confirms that the naïve approach is excessively sensitive to matrix size and is not scalable. Therefore, we developed a different algorithm to overcome these architecture-dependent phenomena.
Operating Environment
The matrix-matrix multiply algorithm was evaluated on the Millennium cluster. Millennium is a heterogeneous network of workstations (NoW or Beowulf cluster) composed of a set of tightly coupled clusters connected together via a high-speed network. The objective was to optimize the matrix-matrix multiplication running on a specific type of computing node. The executable was deployed to a node with a single Intel Pentium3 Katmai series processor running at 550 MHz. Due to the non-exclusive usage policies on Millennium, the chosen processor may have several processes in contention for computer resources. We noticed consistency and repeatability issues when evaluating incremental changes on Millennium, so we continued algorithm and optimization development on local Intel Pentium3 Tualatin series processors running at 1.0 GHz.
Observations
Compiler options
We used the gcc compiler version 2.95-3 available on both our development environment and Millennium. The options that we tried include:
General optimization: -O, -O2, -O4
Architecture-specific: -march=pentiumpro, -mcpu=pentiumpro
Forced optimization: -fstength-reduce, -funroll-all-loops, -fschedule-insns, -fschedule-insns2, -fmove-all-movables, -freduce-all-givs, -malign-double
The –O* optimization flags include a wide variety of general optimization flags, where a larger suffix includes a larger class of optimization features. The architecture-specific options include any assembler instructions specific to the Pentium Pro architecture such as MMX instructions.
Only one pass of the instruction scheduling optimization instead of two (fschedule-insns vs fschedule-insns2) was needed to get performance improvements. The move-all-movables and reduce-all-givs make loop execution more efficient. The first moves the computation of all loop-invariants outside of the loop while the second performs strength-reduction (reduces the required computation within the loop) on traditional loop induction variables.
Furthermore, the compiler option –fstrength-reduce resulted in a performance increase of approximately 30%. This option has the effect of reducing the number of operations required inside the loop by substituting less complicated expressions. For example, if k is the loop iteration variable and Co is constant then setting B = k * Co inside the loop can be reduced to an addition operation B += Co.
The compiler option –malign-double gave us a performance increase of about 20%. This option aligns the addresses of all double variables (8 bytes each) to a multiple of 8. This prevents having a double data value split between two cache lines, or even worse, between two pages in memory. In either case, a cache miss/page fault would occur causing additional latency. According to the Intel optimization manual, this has a high impact and is applicable to many types of programs.
In summary, we included nearly all of the mentioned compiler options in our final executable.
Transposing, Blocking and Tiling
Multiplication by blocks is done in a given code. By default, the matrices provided are stored in column-major format. In the default implementation, the A matrix was traversed in row major order and B was traversed in column-major order. In case of A, an access along the row is highly likely to make cache miss and page fault frequently. By transposing the first matrix A from column to row major before multiplication, both matrices could be traversed using a stride of one. The effect of transposing provides a 10% net increase in performance due to the overhead of transposing the elements.
In the B matrix, stored in a column-major manner, different elements in a same row in a block are likely to reside in different blocks. However, different elements in a same column in a block are highly likely to belong to the same block. So we thought that making the block a long rectangle along the column would give better performance. So in multiplication we used long blocks along row in A, and long blocks along column in B. As we expected we got much better performance. We found that the optimal block size was 32 rows of 256 elements of A and 256 by 32 elements in B. This data occupies a total 8K of the L1 data cache.
Modifications of the Inner Loop
First, we used a local variable to keep track of the partial sums and only write to the C matrix after the total sum was computed. The compiler assigned this variable to a register regardless of whether we explicitly declared it to be a register variable. Since the values in the C matrix are stored sequentially, write combining techniques can be used to minimize the amount of write traffic sent to memory.
We tried to take advantage of pre-fetching and pipelining by explicitly unrolling the inner loop. We didn’t find that there was much performance improvement for some reason. It is possible that the compiler optimization routine took care of the pre-fetching and register assignment.
We changed the order of the outer two loops so that the pages in memory containing portions of the A, B and C matrices could be re-used in the next loop iteration. Qualitatively, we observed a reduced number of page faults using the Windows 2000 Task Manager in the development environment after implementing this change.
The most significant development in optimizing the inner loop came late in the optimization process. We discovered that there was a 40% performance improvement for N < 128 when we calculated two partial sums at once. This optimization had a better overlap of instructions to the integer and floating-point units.
The operands to the floating-point pipeline can only be changed every two clock cycles according to the Pentium4 Optimization manual. When performing two partial sums, the CPU can perform integer micro-operations related to one partial sum while holding the floating-point operands stable for the other partial sum. We cannot explain why there is only minimal benefit for matrices larger than 128.
Program Flow and Syntax
According to the Intel optimization guide, we changed the pointer dereference operations into array indices. Very little difference was noted since we had already included many other optimizations related to compiler options.
We merged the basic_dgemm function within do_block to reduce the subroutine call overhead. There was a minimal improvement, less than 5% for the largest matrix.
Performance on a different platform
We developed and tested the performance of our algorithm on a mobile Pentium Celeron III @ 1 GHz under Cygwin using gcc 3-2 development version. This platform compiles the c-code into Unix-like codes that have underlying NT system calls. Since the code is not completely native, it is not expected to perform as well as
However, there were several factors that were different. This host allowed exclusive access so that the codes were able to use over 90% of the available CPU time. A performance increase was expected since the chip feature size is 0.13 microns resulting in lower gate delays and the system clock is twice as fast. Furthermore, a newer version of gcc allowed additional compiler options to be used.
The following relevant optimizations that were enabled under the new compiler:
-march=pentium3 -mcpu=pentium3 –msse
-fprefetch-loop-arrays -falign-functions -falign-loops
Essentially, the pentium3 march, mcpu and msse options enable the Streaming SIMD Extensions unit, a parallel hardware unit in the Pentium 3. It allows for parallel execution of floating point operations using additional instructions as discussed in the Intel Pentium 3 Software Development Manual. The function and loop alignment options ensure that these addresses are a multiple of 32 bytes corresponding to the beginning of a cache line. These settings probably reduce the number of cache misses in the instruction cache when executing functions and loops.
According to the gcc release notes for version 3.1, software pre-fetching instructions are automatically inserted (using the prefetch assembly instruction) for executables built for the Pentium3. Pre-loading simply lowers the memory stall penalty as opposed to interleaving among the cache and memory traffic using a pre-fetch instruction. The newly compiled code runs approximately 40% faster on the alternate platform.
Figure 3 compares the average run-time performance of the algorithm on Millennium versus the alternate platform. An additional line is included showing the performance improvement obtained by using a newer compiler. This emphasizes the benefits of matching the compiler/optimizer with the hardware environment so that instructions can be issued to make use of high-performance hardware.
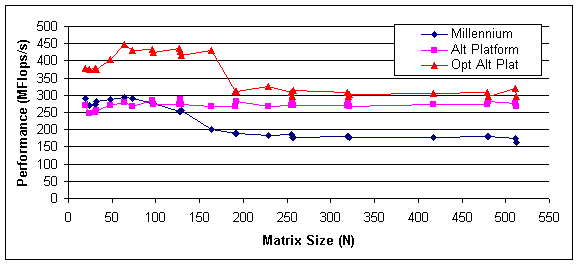
Figure 3 Performance on Millennium versus an Alternate platform, and with a better compiler
Conclusions
The three main factors affecting the matrix multiply performance are using the gcc compiler options “-malign-double”, “-fstrength-reduce” and using a combination transposing and blocking.
Double alignment ensures that no data values are split between cache lines or page boundaries, avoiding data re-arrangement costs and excessive delays caused by page faults. The strength reduction option further increased performance by minimizing the amount of computation within the inner loop. By transposing one matrix before performing the matrix multiplication, a sequential minimal stride of 1 could be used for both matrices. A high computation to memory access ratio was maintained by decomposing the problem through blocking for both the transpose operation and for performing the matrix multiplication.
Testing was performed on Pentium3 laptops or by averaging results on Millennium to measure the effect of changes to the matrix multiplication executable. This approach led to consistent repeatable results so that the effect of a particular changed could be better assessed. Combining these factors along with other favorable techniques led to a scalable, modestly performing algorithm.
As a related side note, more modern compilers are able to take advantage of the specific enhancements in processor technology. Specifically, software pre-fetching and use of the Pentium3 SIMD parallel execution module caused a reasonable performance increase.